How do you teach an algorithm what a good domain name is? 🤖
What is a good .com domain? 🤔
TLDR; I trained a LinearSVC to predict good .com domains with 0.74 accuracy.\
See for yourself how the model performs in action at https://DailyDomainIdeas.com or @DomainIdeaDaily on Twitter 🐦
A good .com domain is 1) Short 2) Simple, and 3) has a Meaning
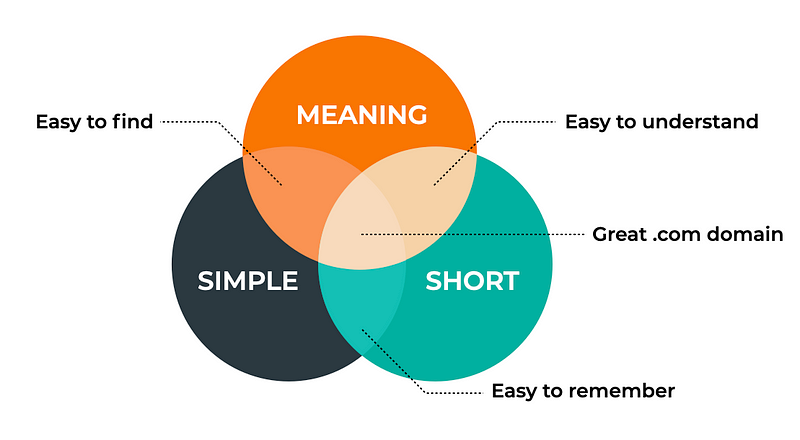
A good .com domain is simple, short and has a meaning
How can an algorithm learn what a good .com is?
I'm training a model to automate myself out of finding daily domain ideas for my side project DailyDomainIdeas.com
I'm not going to lie; I love to browse through lists of expired domains at https://expireddomains.net/, where I'm collecting all my expired domains.
I like the challenge of finding a killer domain in the haystack of domains like hello-1-2-3.com and publishing it on the website. I love this weekly routine.
What I've automated so far
I already automated most of the process with multiple cron jobs.

Cron job #1 wakes up once every night, picks a domain from a list, generates an image for Twitter + Instagram, then goes back to sleep.
1. A cron job that wakes up once every night, picks an available domain, generates a Twitter post, an Instagram post, and then publishes it on the website.

Cron job #2 wakes once every hour, checks in a domain got taken, marks it as taken on the website, notifies me, then goes back to sleep.
2. Another cron job that wakes up once an hour and checks if any of the domains are taken. If so, it marks it as taken on the website and goes back to sleep.
3. And one last cron job that wakes up once every night and posts a tweet with the daily domain idea.
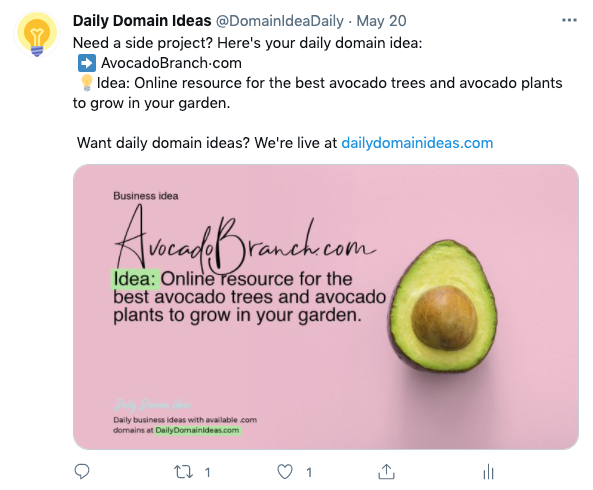
One of my cron jobs automatically creates a Twitter post and posts it once every night
So far, a bunch of my beloved domains have been taken, and some of which I had to say bon voyage to areCatTrim.com, DoggyOwner.com, PoolTemps.com and FreshMocha.com. Seeing domains getting taken is actually a good way for me to tone down my "shiny new object"-syndrome.
One last automation, to rule them all
Anyway, there is one manual task left that I am forced to do every day; Finding good domains for my cron jobs to post.
What is a good .com domain anyway?
To be able to train a model that sifts through expired domains, I had to think about what a good domain actually is. I boiled it down to three main traits:
1. Simplicity
- common words
- common word order 🤖
2. Length
- Shorter than 10 characters
- 1 word or max 2 words
3. Meaning
- Each word has a meaning
- Words belong together
Starting with these 3 criteria, all of the categories are simple and straightforward. Like if a domain is <10 characters or 1 max or 2 words. But one of them needs a deeper understanding: is the domain a common word order?
The difference between blue sky vs. sky sky? ➡️ Common word sequence
How do I know if a domain consists of a typical word order? It is pretty easy to distinguish between a common word sequence like blue sky and the less common sky sky as a human. But how do I teach an algorithm that?
For this, I figured a language model could be of help.
Take this available domain as an example: DogJars.com.
Sure it is short, and it consists of two common words, each word means something, but how easy would it be to remember this domain? How common is the word order?
My strategy to find out if a word order is familiar, and then use it as a feature for training, is to use a BERT language model.
BERT to find common word order in DogJars.com vs. DogFood.com
The goal of using a BERT language model is to find out if the words in the domain are common together, and how typical the word sequence is.
Starting with the BERT language model dictionary, find the index of the second word 'jars' in 'DogJars.com'.
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
jars_index = tokenizer.convert_tokens_to_ids('jars')
If the word exists in the dictionary, it will result in an index other than 100. In this case, 'jars' got the index 25067.
Now that we have the index for 'jars,' the next step is to predict the probability of all the following words after 'dog' would have.
from transformers import BertTokenizer, BertLMHeadModel, BertConfig
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
config = BertConfig.from_pretrained("bert-base-uncased")
config.is_decoder = True
model = BertLMHeadModel.from_pretrained('bert-base-uncased', config=config)
inputs = tokenizer("dog", return_tensors="pt")
outputs = model(**inputs)
pred_logits = outputs.logits
The output from the model is an array with probabilities of the next word after 'dog.' The shape of the pred_logits will look something like this torch.Size([1, 3, 28996]) Where 28996 is the length of the word array.
# Get the softmax probability for the word index
softmax_tensor_value = torch.nn.functional.softmax(pred_logits, dim=2)[0][0][25067] # The index of 'jars'
# Detach the tensor
softmax_array = softmax_tensor_value.detach().cpu().numpy()
# Get the probability value
word_order_probability = np.atleast_1d(softmax_array)[0]
By using SoftMax, we'll get the probability for 'jars' from the word array.
Finally, for 'jars,' the probability of coming after the word 'dog' is 3.0801607e-06 or 0.0003080161%.
To compare, let's try with a word that feels a bit more intuitive to come after 'dog'; food.

What word is more common to come after dog? 'Jars' or 'food'?
'food' gets the index 2833, and the probability to come after the word 'dog' is 0.001891327%.
'food' is therefore roughly 6 times more likely to follow the word 'dog.' Hence, DogFood-com has a more common word order than DogJars-com.
(DogFood-com is unfortunately already taken but feel free to run with DogJars-com, it is still available, thank me later).
The fun part: Training models
All the features are extracted automatically, and the only manual annotation I'm doing is deciding between what a 'good' and 'bad' domain is. I already have a list with ~300 (human picked) good domains. So I mostly spent time labeling 'bad' domains.
I tried to label 'bad' domains pretty harshly. Like GulliversBooking-com, I mean, as a human, I understand the connection between Gulliver and traveling. But I'm looking to train a model that will sift out REALLY good domains. So GulliversBooking-com (also still available, by the way, feel free to steal) is getting a 0, a.k.a is labeled as a 'bad' domain.
Precision vs. recall
Before the training, let's just briefly reflect on precision vs. recall. In the best of worlds, the algorithm would both have a high precision and high recall. But that is not always the case.

Visualization of high/low recall and high/low precision.
Case 1 high precision, low recall
A high precision and lower recall would mean that the model picks out good domains, and all of them are good, ready to get published. The drawback with a low recall, in this case, is that it will miss multiple good ones and misclassify them as bad domains.
Case 2 high recall, low precision
The opposite with high recall and lower precision would mean that the model will find all the good domains, but it would also misclassify bad ones and include them with the good ones.
Case 1 means that I would miss out on good domains to publish (misinterpreted as bad ones), while case 2 would mean more work, forcing me to sift through bad domains scrambled with good ones.
For this application, I will favor case 1. Yes, I might miss out on good domains for my site, but my goal is to automate myself out and not spend more time sifting through bad domains - okey, back to training.
AdaBoost accuracy: 0.71
Starting with AdaBoost, which had ~0.71 accuracy, lower than I was hoping. Similar performance recall but slightly lower on precision for bad domains.
But let's move on to another booster classifier.
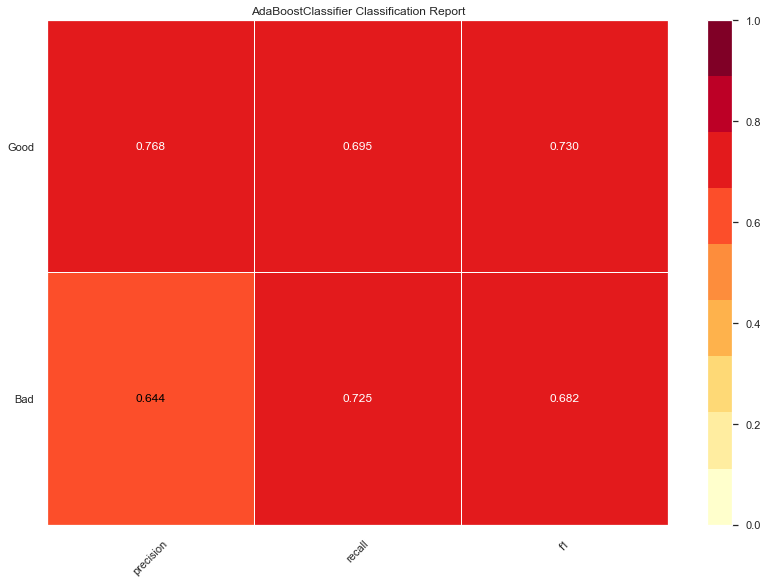
Gradient booster accuracy: 0.69
Very similar results to ADA but performed event slightly worse on the precision for bad domains. So let's try a logistic regression next.
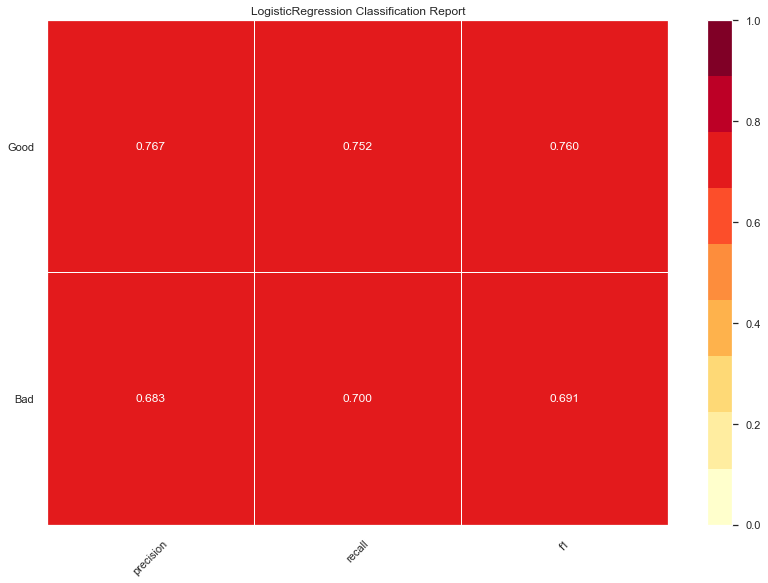
Logistic regression accuracy: 0.72
This is the model performing best so far. Very similar to both previous gradient boosters but slightly better on both precision and recall for the bad domains.
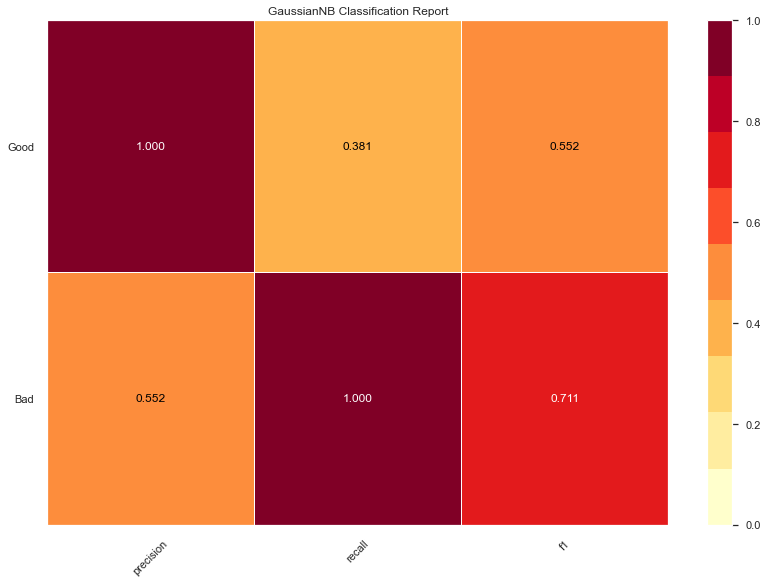
Naive-Bayes accuracy: 0.65
The lowest accuracy so far, high precision on good domains but very low on recall. So the model is very sure and correct on the domains it picked to be good, but it missed a whole lot of other good ones.
The opposite when it comes to bad domains; high recall, so it got all the bad domains. But it also mislabeled a bunch of good domains as bad domains.
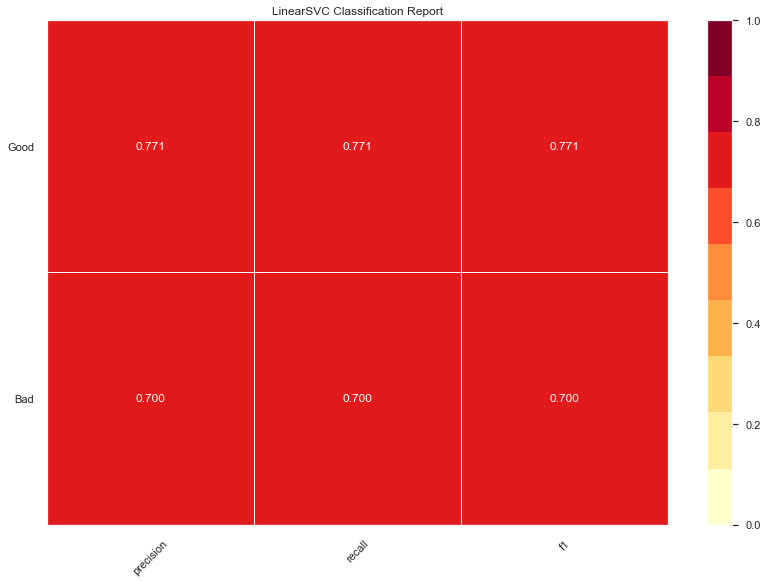
LinearSVC accuracy: 0.74
Definitely the best model so far. Equally high on both precision and recall. Curious to compare this one with how well a KNeightbors will perform.
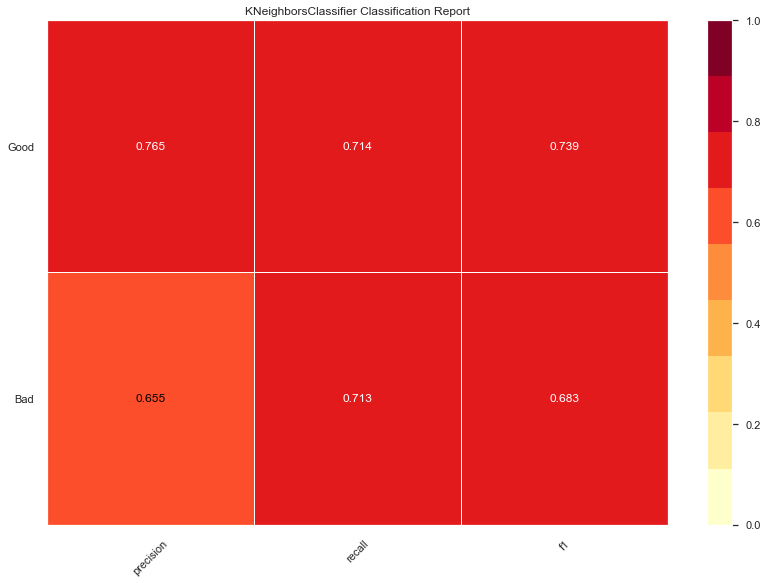
KNeighbors accuracy: 0.71
I'm actually surprised that KNeighbors performed this good. I didn't expect a clustering model to work this well on the dataset. The score is similar to SMV but with a slightly lower precision when it comes to bad domains.
The last model I'm training is a Random Forrest.
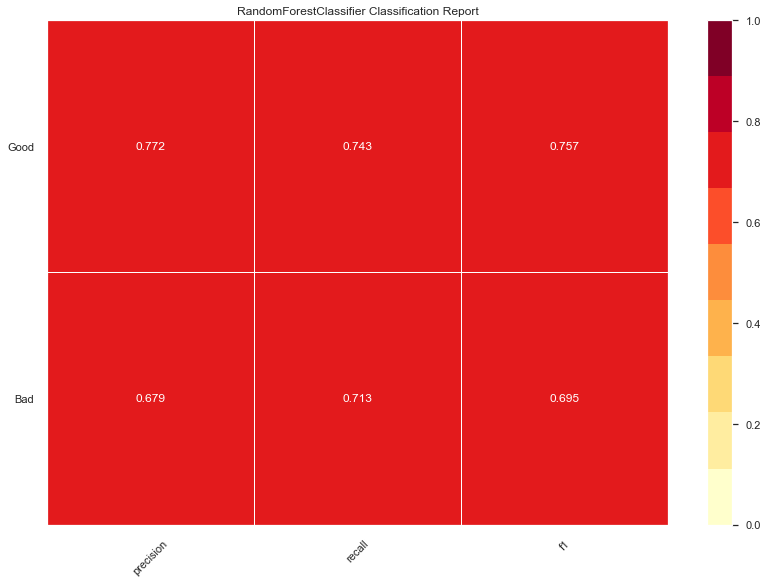
Random Forrest accuracy: 0.73
Also similar to the KNN, but slightly better on precision for bad domains.
The best model on unseen data
Let's try the best model (SVM) on some unseen data. What is not the best place, if not GoDaddy auctions, where domains are sold for over $50,000.
Here are three domains with their demanded prices;\
MoonMom.com ($50,000)\
BlockFirm.com ($50,000)\
MyMall.com ($50,000)
Let's try MoonMom.com.
MoonMom-com - the verdict: it is a good domain ✅

The verdict for MoonMom.com - it is a good domain ✅
Let's try another one I found at ExpiredDomains.net - VotoModo.com
VotoModo-com - the verdict: it is not a good domain🙅♀️ ❌

The verdict for VotoModo.com - it is not a good domain 🙅♀️ ❌
Summary
1) I picked 8 features
- Word commonness (if among 10 000 most common English words)
- Order commonness (BERT model for word order probability)
- Shortness (<10 characters)
- Number of words (1 or max 2 words)
- Word meaning (if word occurs in a dictionary)
- Word length (# characters)
- Occurrence of numbers
- Occurrence of hyphens
2) I trained 7 separate models; Linear SVC 🥇 performed best, followed by Random Forrest 🥈 and Logistic regression 🥉
- LinearSVC 0.74 🥇
- Random Forrest 0.73 🥈
- Logistic regression 0.72 🥉
- ADA 0.71 🏅
- KNeighbors 0.71 🏅
- Gradient boosting 0.69 🏅
- Naive-Bayes 0.65 🏅
Conclusions
I did expect a higher accuracy than 74%; frankly, it surprised me. However, since I'm ultimately the one picking the domains that will get published, I'll go with this slightly low accuracy and aim to add data and fine-tune the model as time goes on.
The next step would be to take a closer look at features and which ones that impacts the models the most.
Feature engineering in the real world 🛠
Do you have any other ideas on features that I could use and extract to further determine if a domain is good or not?
Want to see the algorithm in action? 🤖
Visit https://DailyDomainIdeas.com where I'm (well frankly, the model) publishing a new domain idea every day 💡 or @DomainIdeaDaily on Twitter 🐦
Did you like this project? I'd love your support on Product Hunt 🎉
I've launched Daily Domain Ideas on Product Hunt and your support would mean a lot to me: https://www.producthunt.com/posts/daily-domain-ideas

I've launched Daily Domain Ideas on Product Hunt and would love your support if you like this project
