The new language model stack

Article originally appeared on Sequoia, from Lauren Reeder and Michelle Fradin
ChatGPT unleashed a tidal wave of innovation with large language models (LLMs). We spoke with 33 companies across the Sequoia network, from seed stage startups to large public enterprises, to better understand the applications people are building and the stacks they are using to do so.
We first spoke with them three months ago, then we followed up a few weeks ago to capture the pace of change.
As many founders and builders are in the midst of figuring out their AI strategies themselves, we wanted to share our findings even as this space is rapidly evolving.
1. Nearly every company in the Sequoia network is building language models into their products.
We've seen magical auto-complete features for everything from code (Sourcegraph, Warp, Github) to data science (Hex).
We've seen better chatbots for everything from customer support to employee support to consumer entertainment.
Others are reimagining entire workflows with an AI-first lens:
- visual art (Midjourney),
- marketing (Hubspot, Attentive, Drift, Jasper, Copy, Writer),
- sales (Gong),
- contact centers (Cresta),
- legal (Ironclad, Harvey),
- accounting (Pilot),
- productivity (Notion),
- data engineering (dbt),
- search (Glean, Neeva),
- grocery shopping (Instacart),
- consumer payments (Klarna), and
- travel planning (Airbnb).
These are just a few examples and they're only the beginning.
2. The new stack for these applications centers on language model APIs, retrieval, and orchestration, but open source usage is also growing.
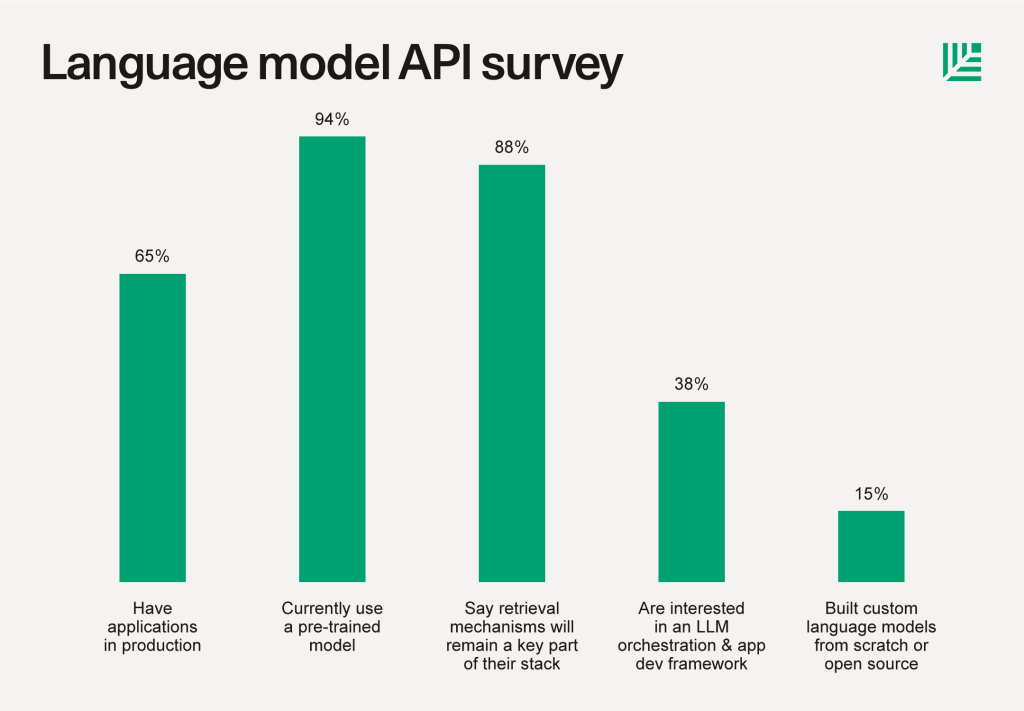
- 65% had applications in production, up from 50% two months ago, while the remainder are still experimenting.
- 94% are using a foundation model API. OpenAI's GPT was the clear favorite in our sample at 91%, however Anthropic interest grew over the last quarter to 15%. (Some companies are using multiple models).
- 88% believe a retrieval mechanism, such as a vector database, would remain a key part of their stack. Retrieving relevant context for a model to reason about helps increase the quality of results, reduce "hallucinations" (inaccuracies), and solve data freshness issues. Some use purpose-built vector databases (Pinecone, Weaviate, Chroma, Qdrant, Milvus, and many more), while others use pgvector or AWS offerings.
- 38% were interested in an LLM orchestration and application development framework like LangChain. Some use it for prototyping, while others use it in production. Adoption increased in the last few months.
- Sub-10% were looking for tools to monitor LLM outputs, cost, or performance and A/B test prompts. We think interest in these areas may increase as more large companies and regulated industries adopt language models.
- A handful of companies are looking into complementary generative technologies, such as combining generative text and voice. We also believe this is an exciting growth area.
- 15% built custom language models from scratch or open source, often in addition to using LLM APIs. Custom model training increased meaningfully from a few months ago. This requires its own stack of compute, model hub, hosting, training frameworks, experiment tracking and more from beloved companies like Hugging Face, Replicate, Foundry, Tecton, Weights & Biases, PyTorch, Scale, and more.
Every practitioner we spoke with said AI is moving too quickly to have high confidence in the end-state stack, but there was consensus that LLM APIs will remain a key pillar, followed in popularity by retrieval mechanisms and development frameworks like LangChain. Open source and custom model training and tuning also seem to be on the rise. Other areas of the stack are important, but earlier in maturity.

3. Companies want to customize language models to their unique context.
Generalized language models are powerful, but not differentiating or sufficient for many use cases. Companies want to enable natural language interactions on *their *data — their developer docs, product inventory, HR or IT rules, etc. In some cases, companies want to customize their models to their *users' *data as well: your personal notes, design layouts, data metrics or code base.
Right now, there are three main ways to customize language models (for a deeper technical explanation, see Andrej's recent State of GPT talk at Microsoft Build):
Train a custom model from scratch. Highest degree of difficulty.
This is the classical and hardest way to solve this problem. It typically requires highly skilled ML scientists, lots of relevant data, training infrastructure and compute. This is one of the primary reasons why historically much natural language processing innovation occurred within mega-cap tech companies.
BloombergGPT is a great example of a custom model effort outside of a mega-cap tech company, which used resources on Hugging Face and other open source tooling.
As open source tooling improves and more companies innovate with LLMs, we expect to see more custom and pre-trained model usage.
Fine-tune a base model. Medium degree of difficulty.
This is updating the weights of a pre-trained model through additional training with further proprietary or domain-specific data. Open-source innovation is also making this approach increasingly accessible, but it still often requires a sophisticated team.
Some practitioners privately admit fine-tuning is much harder than it sounds and can have unintended consequences like model drift and "breaking" the model's other skills without warning.
While this approach has a greater chance of becoming more common, it is currently still out of reach for most companies. But again, this is changing quickly.
Use a pre-trained model and retrieve relevant context. Lowest degree of difficulty.
People often think they want a model fine-tuned just for them, when really they just want the model to reason about their information at the right time.
There are many ways to provide the model the right information at the right time:
- Make a structured query to a SQL database
- Search across a product catalog
- Call some external API or use embeddings retrieval
The benefit of embeddings retrieval is that it makes unstructured data easily searchable using natural language. Technically, this is done by taking data, turning it into embeddings, storing those in a vector database, and when a query occurs, searching those embeddings for the most relevant context, and providing that to the model. This approach helps you hack the model's limited context window, is less expensive, solves the data freshness problem (e.g. ChatGPT doesn't know about the world after September 2021), and it can be done by a solo developer without formal machine learning training. Vector databases are useful because at high scale they make storing, searching and updating embeddings easier.
So far, we've observed larger companies stay within their enterprise cloud agreements and use tools from their cloud provider, while startups tend to use purpose-built vector databases.
However, this space is highly dynamic. Context windows are growing (hot off the presses, OpenAI just expanded to 16K, and Anthropic has launched a 100K token context window). Foundational models and cloud databases may embed retrieval directly into their services. We're watching closely as this market evolves.
4. Today, the stack for LLM APIs can feel separate from the custom model training stack, but these are blending together over time.
It can sometimes feel like we have a tale of two stacks: the stack to leverage LLM APIs (more closed-source, and geared towards developers) versus the stack to train custom language models (more open source, and historically geared towards more sophisticated machine learning teams).
Some have wondered whether LLMs being readily available via API meant companies would do less of their own custom training. So far, we're seeing the opposite. As interest in AI grows and open-source development accelerates, many companies become increasingly interested in training and fine-tuning their own models.
We think the LLM API and custom model stacks will increasingly converge over time. For example, a company might train its own language model from open source, but supplement with retrieval via a vector database to solve data freshness issues. Smart startups building tools for the custom model stack are also working on extending their products to become more relevant to the LLM API revolution.
5. The stack is becoming increasingly developer-friendly.
Language model APIs put powerful ready-made models in the hands of the average developer, not just machine learning teams. Now that the population working with language models has meaningfully expanded to all developers, we believe we'll see more developer-oriented tooling.
For example, LangChain helps developers build LLM applications by abstracting away commonly occurring problems:
- Combining models into higher-level systems
- Chaining together multiple calls to models
- Connecting models to tools and data sources
- Building agents that can operate those tools
- Helping avoid vendor lock-in by making it easier to switch language models
Some use LangChain for prototyping, while others continue to use it in production.
6. Language models need to become more trustworthy (output quality, data privacy, security) for full adoption.
Before fully unleashing LLMs in their applications, many companies want better tools for handling data privacy, segregation, security, copyright, and monitoring model outputs.
Companies in regulated industries from fintech to healthcare are especially focused on this. They are asking for software to alert, or ideally prevent, models from generating errors/hallucinations, discriminatory content, dangerous content, or exposing new security vulnerabilities. Robust Intelligence in particular has been tackling many of these challenges, with customers including Paypal, Expedia and others.
Some companies are also concerned about how data shared with models is used for training: for instance, few understand that ChatGPT Consumer data is default used for training, while ChatGPT Business and the API data are not. As policies get clarified and more guardrails go into place, language models will be better trusted, and we may see another step change in adoption.
7. Language model applications will become increasingly multi-modal.
Companies are already finding interesting ways to combine multiple generative models to great effect: Chatbots that combine text and speech generation unlock a new level of conversational experience. Text and voice models can be combined to help you to quickly overdub a video recording mistake instead of re-recording the whole thing. Models themselves are becoming increasingly multi-modal. We can imagine a future of rich consumer and enterprise AI applications that combine text, speech/audio, and image/video generation to create more engaging user experiences and accomplish more complex tasks.
8. It's still early.
AI is just beginning to seep into every crevice of technology. Only 65% of those surveyed were in production today, and many of these are relatively simple applications. As more companies launch LLM applications, new hurdles will arise — creating more opportunities for founders. The infrastructure layer will continue to evolve rapidly for the next several years. If only half the demos we see make it to production, we're in for an exciting ride ahead. It's thrilling to see founders from our earliest-stage Arc investment to Zoom all laser focused on the same thing: delighting users with AI.
If you're founding a company that will become a key pillar of the language model stack or an AI-first application, Sequoia would love to meet you.
Thank you to all the founders and builders who contributed to this work, and Sequoia Partners Charlie Curnin, Pat Grady, Sonya Huang, Andrew Reed, Bill Coughran and friends at OpenAI for their input and review.

The number of new AI startups right now is insane. But big incumbents are also acting quickly to integrate AI.
I think the startups that do well in this period will be those that…
Otherwise, if you're doing something like building an Intercom clone with AI on top, then Intercom will simply win.
Interesting point #3. I think a ton of the scramble around AI actually falls in that category (companies slapping "AI" on top of existing products). But it would be a unique approach to start building fresh with AI to actually solve the problem at hand, not simply augment existing solutions. Good point.
Ai is Like a Pure Love but i also have created a wonderful Web with the HELP of Ai Please Review it is Good Done to work like that? reagards apklia
Love the insights !
On your points #5 "making ML more developer friendly, not just accessible for data scientists". Beside LLMs/NLP use cases, do you think ML accessibility is also in other domains (Speech to text, Computer vision, etc.) ?
Interesting
I see all these companies advertising how AI can produce content and assets for a business, all in their brand voice and tone. But what about personal brands?
Are there any AI tools where you can train the model on.... yourself? Anytime I use an LLM or chat product it doesn't sound like me. Curious if anyone is working on that pain point
Fantastic presentation and analysis of the data. Very helpful!
In my company, we are also using chatgpt to do some manual work and create more products. The results are being great :)
This is super helpful, thank you!
I see Langchain made the cut in the frameworks. I've been using it for a while but it's becoming less necessary with the latest ChatGPT API updates IMO. I see some really cool options here that I hadn't considered though.
More creative companies will be able to bring more help through their api in the future
Well thanks for your dedicated post. We're also developing an AI tool for storage and quick capture for knowledge lovers to easily capture and consume knowledge from multiple sources called SaveDay. Let's check out our website for more information: https://www.save.day/?utm_source=ih&utm_medium=comment&utm_campaign=specific
This comment was deleted a year ago.