We built intelligent context management so you never hit token limits mid-conversation
Hey IndieHackers 👋
I'm building AI Nexus - a multi-model AI interface that lets you access GPT-4, Claude, Gemini, and 100+ other models through one workspace.
One of the most frustrating problems with AI chat tools is hitting token limits in the middle of important conversations. You're deep into a complex discussion, then suddenly: "Your context is too long. Please start a new conversation."
So we built Intelligent Context Management to solve this.
The Problem
Every AI model has a context window limit (how much text it can "remember" at once). For example:
GPT-4 Turbo: 128k tokens (~96k words)
Claude 3.5 Sonnet: 200k tokens (~150k words)
GPT-3.5: 16k tokens (~12k words)
When you're working on complex projects with:
Long conversation histories
Uploaded files (code, docs, data)
System prompts
Project context
...you can hit these limits fast. Most tools just error out or silently truncate your context, losing important information.
Our Solution: Smart Context Management
We built a visual context manager that shows you exactly what's using your tokens and gives you control:
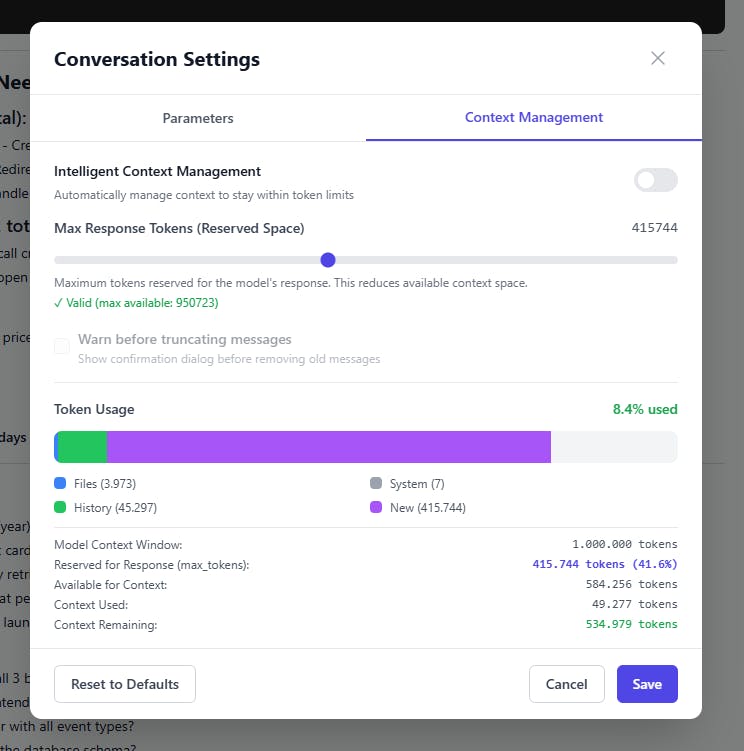
What it does:
1. Real-time token tracking Visual breakdown of where your tokens are going:
📁 Files (project context)
💬 History (conversation)
⚙️ System prompts
✨ New message space
2. Intelligent auto-management Toggle on "Intelligent Context Management" and AI Nexus automatically:
Keeps your context within limits
Prioritizes recent messages
Preserves important context (files, system prompts)
Warns before truncating anything
3. Response space reservation Set how many tokens to reserve for the model's response. The UI shows you exactly how much context space remains.
4. Manual control You can see:
Model context window: 1,000,000 tokens (in this case, Sonnet 4.5)
Reserved for response: 415,744 tokens (41.6%)
Available for context: 584,256 tokens
Context used: 49,277 tokens
Context remaining: 534,979 tokens ✅
Why This Matters
Most AI chat tools treat context as a black box. You don't know:
How much context you're using
What's taking up space
When you're about to hit limits
What gets truncated when you do
This creates anxiety and breaks complex workflows.
With transparent context management:
✅ No surprise errors
✅ Work with large files confidently
✅ Have longer, more valuable conversations
✅ Understand your costs (more tokens = higher costs)
Technical Implementation
For the curious:
Backend:
Calculate token counts using model-specific tokenizers
Track context across: files, messages, system prompts, tools
Implement sliding window with semantic preservation
Warn before auto-truncation
Frontend:
Real-time token visualization
Color-coded breakdown (files=blue, history=green, system=gray, new=purple)
Responsive slider for response token reservation
Validation against model limits
Edge cases handled:
Different models, different context windows
Switching models mid-conversation
Adding/removing files
Multi-turn conversations with tool calls
What's Next
We're quickly preparing for our free beta (3 months free, then €5/month). You bring your own OpenRouter API key and get access to 100+ models.
Other features:
Projects - Group conversations, share context files
Conversation branching - Explore parallel ideas
Prompt library - Save and reuse what works
MCP server integration - Extend with custom tools
Questions for the community:
How do you currently handle long conversations in ChatGPT/Claude? Start fresh? Manually summarize?
Would you pay for better context management? Or is this table-stakes?
What other context-related problems do you face? We're thinking about:
Auto-summarization of old messages
Smart context compression
Context presets (e.g., "keep last 10 messages + all files")

