What is Text Mining, NLP Analysis and the N-gram model?

TLDR
This article will discover the number of words that appear in “Sonnet,” and by analyzing high-frequency words, know Shakespeare’s intentions and preferences. Also, I will use part-of-speech tagging and n-gram models to improve our understanding of the article.
 Source: Giphy
Source: Giphy
Outline
-
Intro
-
Preliminary preparation
-
Text data preprocessing
-
Split words
-
Count the number of words in the article
-
Stop words
-
Calculate the frequency of the top 20 words
-
Conclusion or Final thoughts
-
Part of Speech Tagging
-
Training The Model
-
Closing Thought
Intro
Text mining is a large part of artificial intelligence. It helps computers understand, interpret, and manipulate human language. For example, how to analyze customers’ reviews for a product. How do chatbots mine for users' emotional information? How to extract the information people want from an article. This article analyzes Shakespeare’s “The Sonnets,” which can provide digital help for researchers of literature and history.
 Source: Giphy
Source: Giphy
Text Data Preprocessing
Since there are many abbreviations and punctuation marks in the “Sonnets,” I need to restore these abbreviations and remove useless punctuation marks. The operation steps are as follows:
Regular Expression is a sequence of characters that form a search pattern. RegEx can be used to check if a string contains the specified search pattern.
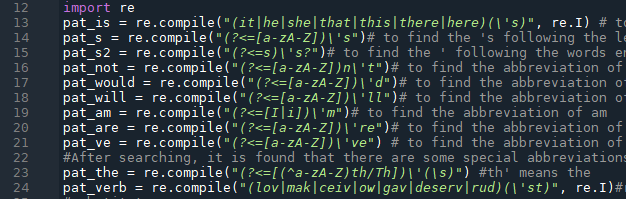 Find specific patterns in string
Find specific patterns in string
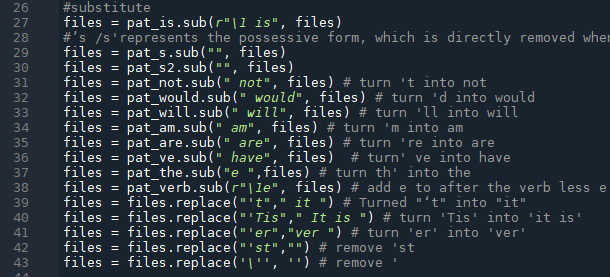 Pattern substitution
Pattern substitution
- As shown in line 12, first load regular expression packages.
- As shown in line 13, 's is following the pronouns, such as it's.
- As shown in line 14, 's is following the noun, such as world's.
- As shown in line 15, ' is following the words ending by s, such as others', cars'.
- As shown in line 16, 't, such as doesn't.
- As shown in 17, 'd such as I'd.
- As shown in line 18, 'll such as he'll.
- As shown in line 19, 'm such as I'm.
- As shown in line 20, 're such as they're. As shown in line 21, 've such as I've.
- After that, there are some abbreviations in the source file.
- As shown in line 23, th'&Th' means "the","The".
- As shown in line 24, in medieval English, verbs followed by second person are usually followed by 'st', which has no special meaning. So it is directly removed when restored.
- As shown in line 27, 's following the pronoun is replaced by is.
- As shown in line 29, 30, 's indicates the possessive form, which is removed when restoring, but the verb prototype is retained.
- As shown in line 31, 't is replaced by "not".
- As shown in line 32, 'd is turned into "would".
- As shown in line 33, 'll is replaced by "will".
- As shown in line 34, 'm is turned into "am".
- As shown in line 35, 're is replaced by "are".
- As shown in line 36, 've is turned into have.
- As shown in line 37, 'th is replaced by the.
- As shown in line 39, 't is turned into 'it'.
- As shown in line 40, 'Tis' is replaced by "This is''.
- As shown in line 41, 'er' is turned into 'ver'. As shown in line 42, remove 'st'.
I don't consider lowercase and uppercase of words, uniformly converted to lowercase. Remove non-word characters.
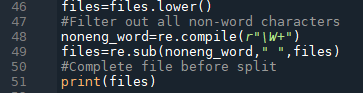 Lowercase and remove non-English words
Lowercase and remove non-English words
 Result of Lowercase and remove non-English words
Result of Lowercase and remove non-English words
Split Words
Split the paragraph into words.

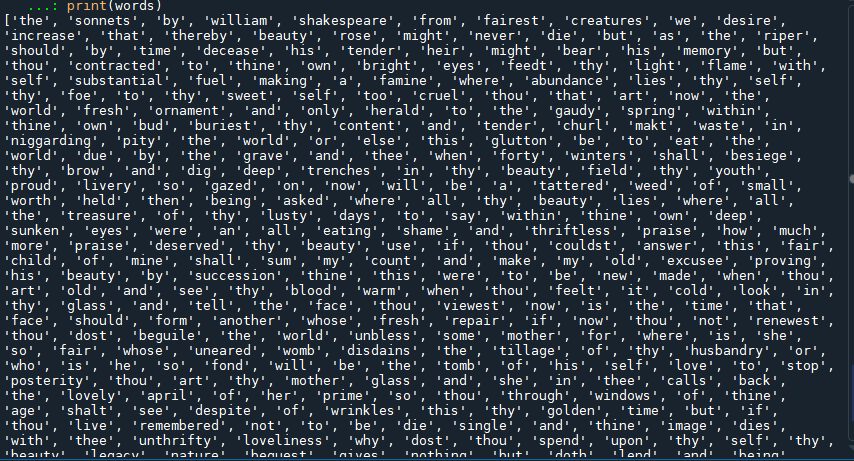 Result of split words
Result of split words
Count the number of words in the poetry
Circulate each word in “words, which is word after split.” if it is a word, count+1
 Count the number of words in the poetry
Count the number of words in the poetry
Count the number of words after split, get the result:
 The total number of words
The total number of words
Stop words
Stopwords are English words which don’t add much meaning to a sentence. They can safely be ignored without sacrificing the meaning of the sentence. For example, the words like the, he, have, etc. So I put these words in the txt file and tell Python to remove these stop words.
 Read stopwords and get the new words.
Read stopwords and get the new words.
Calculate the frequency of the top 20 words
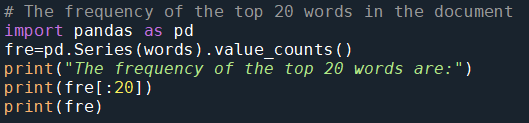 Frequency of the top 20 words
Frequency of the top 20 words
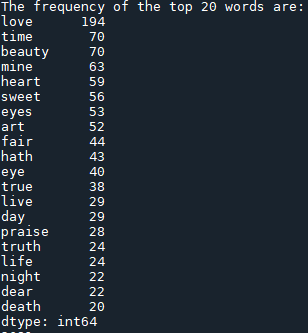 Result of top 20 words
Result of top 20 words
Here are the top 20 words in the poem “The Sonnets.”
Conclusion
In "The Sonnets,” Shakespeare repeats the word "love" 194 times, which shows that he likes to use this word very much, and it’s the main theme of the poem. Shakespeare depicts a multi-faceted image of love. Love is so powerful that it can defeat all obstacles. He believes true love and real love, like the stars can always be seen and never changing.
 Source: Giphy
Source: Giphy
In "The Sonnets,” Shakespeare repeats the word "Time" 70 times, the second most common of all keywords. Shakespeare often personifies time. Shakespeare describes time as a tyrant and consumption of love and beauty. Shakespeare describes time as a “bloody tyrant” (Sonnet 16), “devouring” and “swift-footed” (Sonnet 19), “injurious hand” and “age' s cruel knife” (Sonnet 63). Time comes in many different forms, most of which are described as negative.
 Source: Giphy
Source: Giphy
In "The Sonnets'', Shakespeare repeats the word "beauty" 70 times, the second most common of all keywords. Beauty, irrefutably, is a common theme throughout the Shakespearean sonnets. Beauty in Shakespeare’s Sonnets is represented in two dimensions: the physical beauty and the spiritual beauty. For example, he used the word "beauty" many times to describe the beauty of humans and the beauty of the heart.
 Source: Giphy
Source: Giphy
Part of Speech Tagging
Parts of speech tagging simply refers to assigning parts of speech to individual words in a sentence. The parts of speech are nouns (NN), verbs (VB), adjectives (JJ), etc. For details, please refer to the part-of-speech tagging table.
I word_tokenize all the words after preprocessing named “files” and then put these into dict. And then pos tag these dict and name them as tag.
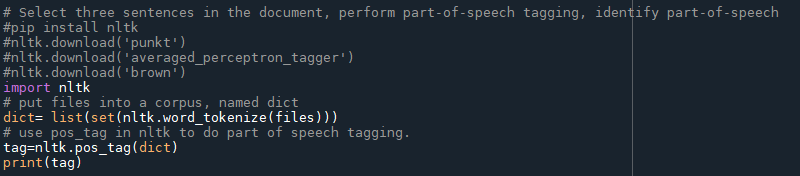 Part of speech tagging
Part of speech tagging
Result as follows:
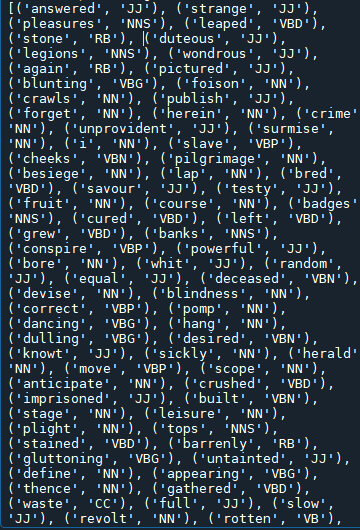 Result of tagging
Result of tagging
The meaning of part of speech: The parts of speech are important because they show us how the words relate to each other. Now, they are just words, they don't really tell us something. But, as soon as we assign each word a role (a part of speech), and put them into a sentence, we actually get something meaningful: "touch my breast."
Train the Model
The Brown Corpus was the first million-word electronic corpus of English, created in 1961 at Brown University. Please note all the words in the Sonnets are put into the corpus as a whole data set, and we choose 90% of the whole data as a training set to train the model.
In this example, we are using DefaultTagger as the backoff tagger. Whenever the UnigramTagger is unable to tag a word, backoff tagger, i.e. DefaultTagger, in our case, will tag it with ‘NN’. DefaultTagger is most useful when it gets to work with the most common part-of-speech tag. That's why a noun tag is recommended.
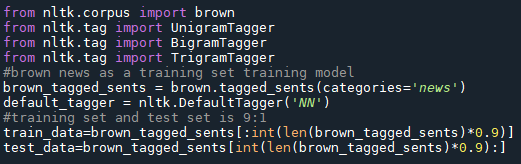 Train the model
Train the model
Unigram: Unigram tagger is a tagger that only uses a single word as its context for determining the POS (Part-of-Speech) tag.
Bigram: Unigram tagger is a tagger that only uses two words as its context for determining the POS (Part-of-Speech) tag.
Trigram: Unigram tagger is a tagger that only uses three words as its context for determining the POS (Part-of-Speech) tag.
If we didn't find the default tagger, then setting backoff. If one tagger doesn’t know how to tag a word, the word would be passed to the next tagger and so on until there are no backoff taggers left to check.
 Train the n-gram model
Train the n-gram model
 Result of n-gram model
Result of n-gram model
Unigram just considers the conditional frequency of tags and predicts the most frequent tag for every given token. Bigram is more accurate than the other two, However, the Unigram tagger has better coverage.
Closing Thoughts:
Since this is poetry, there is no need for prediction, we just need to know how to do lexical tagging. If we want to design automatic text filling, or speech prediction, then we can proceed to prediction. I’ll update my knowledge about the N-gram model and visualization of part-of-speech tagging in the next article, please stay tuned.

The global NLP industry is expected to reach US$42.04 billion by 2026, with a CAGR of 21.5%, according to Mordor Intelligence.
Now that you understand the importance of NLP, discover more information here: https://bit.ly/3blZfj0
For more interesting topics: https://bit.ly/3AKiP3q
NLP for the future
Natural language processing (NLP) is a branch of artificial intelligence that deals with the interaction between computers and human languages.
Find out more about NLP and how does it work here: https://bit.ly/3blZfj0
The global NLP industry is expected to reach US$42.04 billion by 2026, with a CAGR of 21.5%, according to Mordor Intelligence.
Now that you understand the importance of NLP, discover more information here: https://bit.ly/3blZfj0
What is Natural Language Processing?
Natural language processing (NLP) is a branch of artificial intelligence that deals with the interaction between computers and human languages. NLP is used to develop applications that can understand human language and respond in a way that is natural for humans.
NLP is used in many different applications, such as: text mining, machine translation, speech recognition, and information retrieval.
To learn more about NLP: https://bit.ly/3A2BHKD